American versus Chinese LLMs: a Game of Capabilities for Enterprise Adoption
From the TightSpreads Substack.
The Geopolitical Bifurcation of AI Development
U.S. AI investment is primarily driven by national security and defense considerations relative to foreign counterparts. This competitive landscape aligns with the “Two Worlds” framework set by Morgan Stanley Thematic Research, where they predict Large Language Model (LLM) development bifurcates into two distinct strategic directions:
The American Frontier: U.S.-based labs prioritize breakthrough technical capabilities, consistently pushing the boundaries of model performance.
The Chinese Strategy: Competitors in the East emphasize cost reduction and pragmatic, customer-centric applications over raw technical milestones.
Scaling Laws and the 2026 Performance Leap
Investor sentiment often struggles to internalize the implications of non-linear technological growth, specifically regarding the 10x increase in compute magnitude slated for the next generation of American LLMs. Should current scaling laws remain consistent through 2026, the market can anticipate the following shifts in 1H26:
Expert-Level Autonomy: Frontier LLMs are projected to perform the majority of human tasks at or above the level of a human expert.
Performance Divergence: Due to significant constraints in available computational power, Chinese models are unlikely to match these performance breakthroughs within the same timeframe.
Pragmatic Optimization: While trailing in raw capability, Chinese providers are expected to lead in delivering affordable, high-utility AI solutions tailored to practical consumer needs.
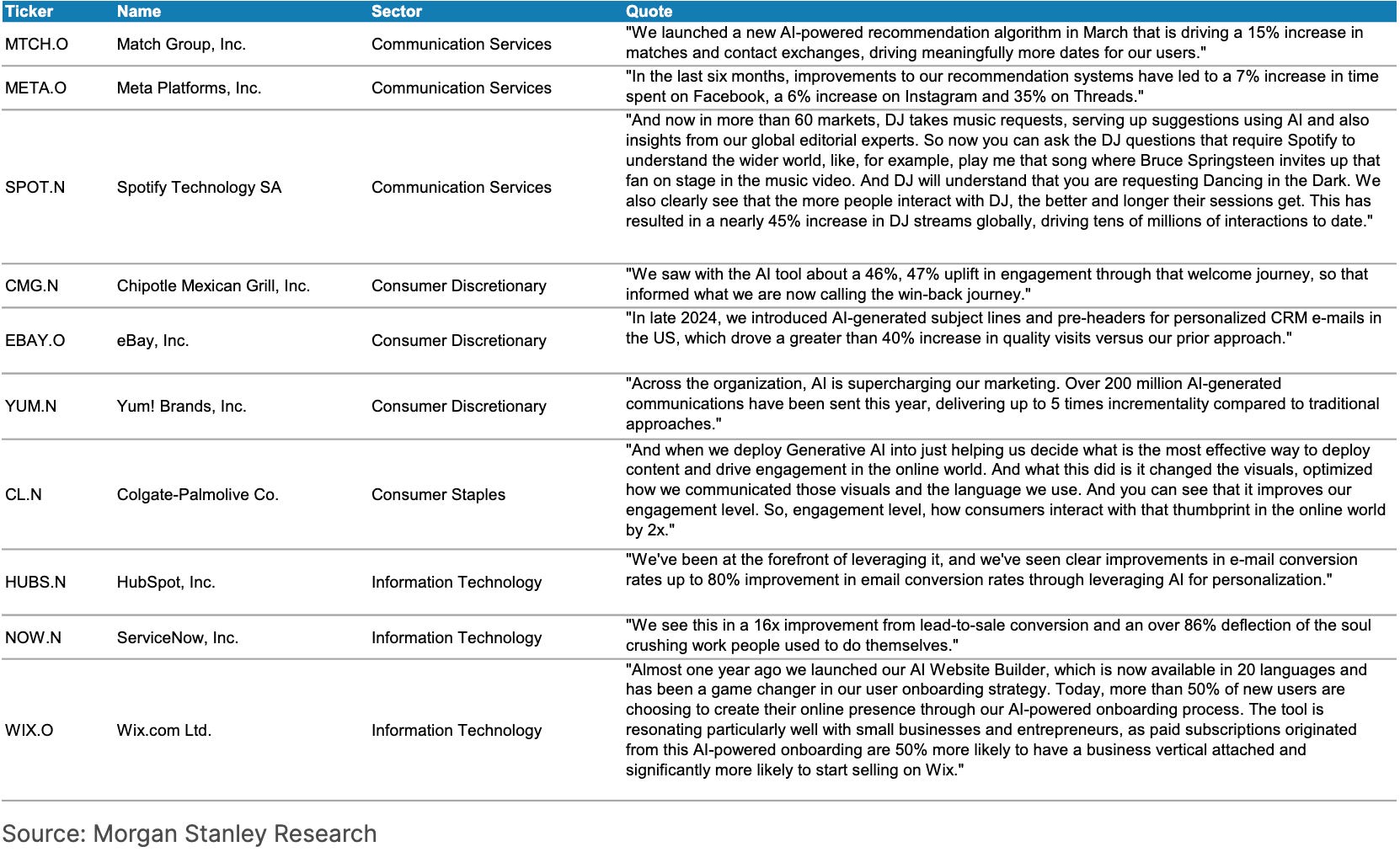
The following chart, from Artificial Analysis, underscores the rapid advances in AI capabilities in 2025:
Frontier Language Model Intelligence, Over Time
Source: Artificial Analysis Intelligence Index
For a deeper dive into the delta in cost, capabilities and use cases for open source LLMs relative to proprietary models check out this AndreesenHorowitz/OpenRouter study.
Here are some notable takeaways from the article:
“Proprietary systems continue to define the upper bound of reliability and performance, particularly for regulated or enterprise workloads. OSS models, by contrast, offer cost efficiency, transparency, and customization, making them an attractive option for certain workloads. The equilibrium is currently reached at roughly 30%….These models are not mutually exclusive; rather, they complement each other within a multi-model stack that developers and infrastructure providers increasingly favor.”
Among the open source models:
“The market has since become both broader and deeper, with usage diversifying significantly. New entrants like Qwen’s models, Minimax’s M2, MoonshotAI’s Kimi K2, and OpenAI’s GPT-OSS series all grew rapidly to serve significant portions of requests, often achieving production-scale adoption within weeks of release. This signals that the open source community and AI startups can achieve quick adoption by introducing models with novel capabilities or superior efficiency. By late 2025, the competitive balance had shifted from near-monopoly to a pluralistic mix. No single model exceeds 25% of OSS tokens, and the token share is now distributed more evenly across five to seven models. The practical implication is that users are finding value in a wider array of options, rather than defaulting to one ‘best’ choice … proprietary models still handle the bulk of coding assistance overall (the gray region), reflecting strong offerings like Anthropic’s Claude.”
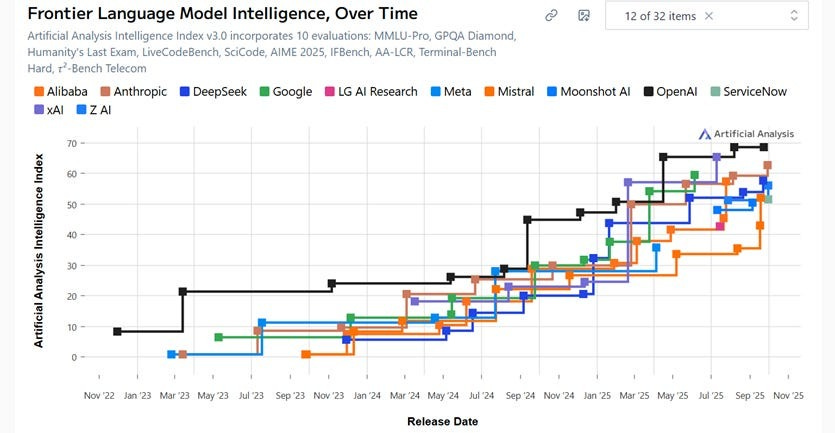
In terms of LLM use cases, one of the highest value add uses is software coding, and in this application, the proprietary models dominate:
“proprietary models still handle the bulk of coding assistance overall (the gray region), reflecting strong offerings like Anthropic’s Claude.” This is especially important because coding is now the dominant, token-weighted use case — in early 2025, coding represented 11% of token volume, but toward the end of 2025, this share exceeded 50%. The following exhibit from the report highlights proprietary model dominance in coding use cases:
Programming Breakdown by OSS:
Source: OpenRouter
The study also claims that model pricing has been only a modest indicator of usage
On the contrary, one could extrapolate that to say model pricing is more indicative of greater model performance capabilities for at least some of the more computationally-intensive models:
Cost vs. Usage Highlighted by Model Authors:

Source: OpenRouter
Resources to help investors assess the potential non-linear rate of AI improvement as provided by MS:
In an interview Elon Musk stated his view that applying 10x compute to LLM training will double the model’s “intelligence.”
In a blog post Julian Schrittwieser, co-first author on AlphaGo, AlphaZero, and MuZero, all owned by DeepMind Technologies, describes his view with respect to the continuing non-linear rate of LLM capability improvements.
METR is an independent entity that provides excellent data with respect to the rate of improvement in LLM capabilities.
A team at Meta, Virginia Tech, and Cerebras Systems recently published a paper entitled “Demystifying Synthetic Data in LLM Pre-training: A Systematic Study of Scaling Laws, Benefits, and Pitfalls.” In this paper, the research team assess whether there are limits in improvements in LLMs as computational power, and synthetic data, used to train these models increases. Synthetic data is “text generated by pre-existing models or automated pipelines,” and the research team notes that “synthetic data presents a compelling potential avenue for augmenting — or perhaps eventually replacing — traditional human-generated corpora during the foundational pre-training phase.”
A recent paper from a team of Google researchers details an approach to LLM architecture that can lead to self-evolving models: “we propose ReasoningBank, a novel memory framework that distills generalizable reasoning strategies from an agent’s self-judged successful and failed experiences. At test time, an agent retrieves relevant memories from ReasoningBank to inform its interaction and then integrates new learnings back, enabling it to become more capable over time.”
The Two Worlds framework further manifests in a widening gap between a concentrated segment of specialized developers and early adopters versus the broader population, whose engagement remains limited to tangential or passive applications of the technology. An essay from Anthropic executive, Jack Clark, described this dynamic well:
“By the summer I expect that many people who work with frontier AI systems will feel as though they live in a parallel world to people who don’t. And I expect this will be more than just a feeling — similar to how the crypto economy moved oddly fast relative to the rest of the digital economy, I think we can expect the emerging ‘AI economy’ to move very fast relative to everything else. And in the same way the crypto economy also evolved a lot — protocols! Tokens! Tradable tokens! Etc — we should expect the same kind of rapid evolution in the AI economy. But a crucial difference is that the AI economy already touches a lot more of our ‘regular’ economic reality than the crypto economy. So by summer of 2026 it will be as though the digital world is going through some kind of fast evolution, with some parts of it emitting a huge amount of heat and light and moving with counter-intuitive speed relative to everything else. Great fortunes will be won and lost here, and the powerful engines of our silicon creation will be put to work, further accelerating this economy and further changing things. And yet it will all feel somewhat ghostly, even to practitioners that work at its center. There will be signatures of it in our physical reality — datacenters, supply chain issues for compute and power, the funky AI billboards of San Francisco, offices for startups with bizarre names - but the vast amount of its true activity will be occurring both in the digital world, and in the new spaces being built and configured by AI systems for trading with one another — agents, websites meant only for consumption by other AI systems, great and mostly invisible seas of tokens being used for thinking and exchanging information between the silicon minds.”
What should the stock implications be in 2026 as a result of this “Two Worlds” dynamic?
High volatility is expected across AI-related sectors—including Enablers, Adopters, and Infrastructure—as market sentiment oscillates between skepticism regarding tangible returns and optimism driven by successful applications in software development and professional services. Periods of skepticism and resulting stock weakness present strategic buying opportunities, as the long-term trajectory of AI capabilities and economic benefits likely exceeds current market pricing.
This bullish fundamental outlook is supported by three primary drivers:
Macroeconomic Impact: Analysis of AI adoption and the future of work indicates that the S&P 500 could realize annual benefits exceeding $900 billion.
Corporate Inflection: Data suggests a shift in corporate adoption, with AI integration reaching levels of financial materiality.
The Training Compute Inflection: The high-volume availability of NVIDIA Blackwell GPUs marks a critical technical milestone. Consequently, the top five American LLM developers are projected to apply approximately 10x the computational power to train next-generation models compared to those currently in the market.
As of July 2025, 412 stocks ($8.7 trillion of market cap) have increased their AI exposure and 259 stocks ($8.5 trillion of market cap) have AI as a more material factor in their business. 102 stocks ($2.4 trillion of market cap) have increased in both exposure to and materiality of AI.
MS AI Value Creation Opportunities: Relative Industry Rankings:
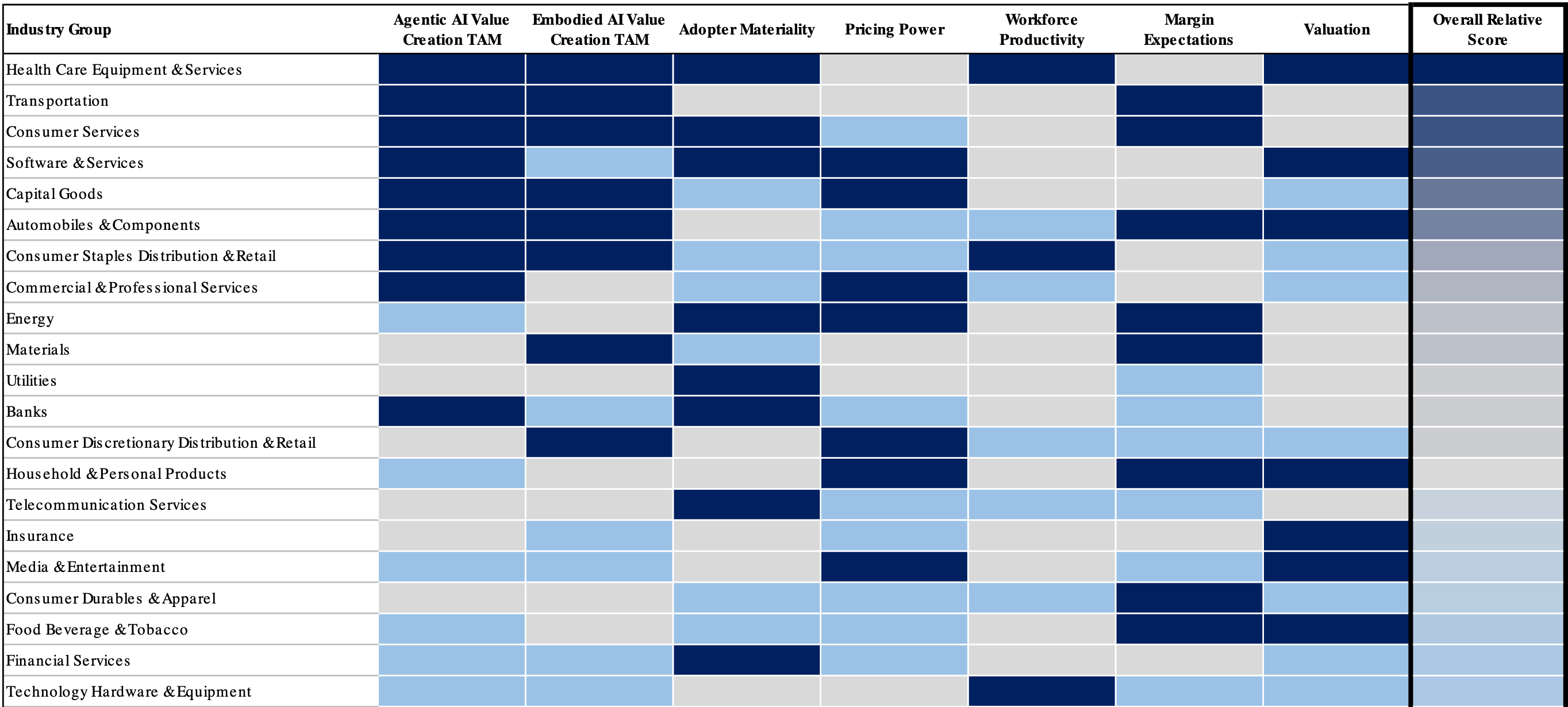
If scaling laws hold, models should double the capabilities of current models. Although this is a significant claim OpenAI’s “GPDVal” score is useful in justifying the numbers — this score
“measures model performance on tasks drawn directly from the real-world knowledge work of experienced professionals across a wide range of occupations and sectors, providing a clearer picture on how models perform on economically valuable tasks…. [W]e found that frontier models can complete GDPval tasks roughly 100x faster and 100x cheaper than industry experts.“
So let’s look at the magnitude of progress in 2025.
For example, Grok 4 (introduced in July 2025) scored 24% (meaning the model was on par with human experts with respect to 24% of the tasks), while GPT-5.2 (introduced on December 12, 2025) scored an impressive 71%.
The following GDPVal leaderboard charts the recent rapid increase in Frontier LLM capabilities:
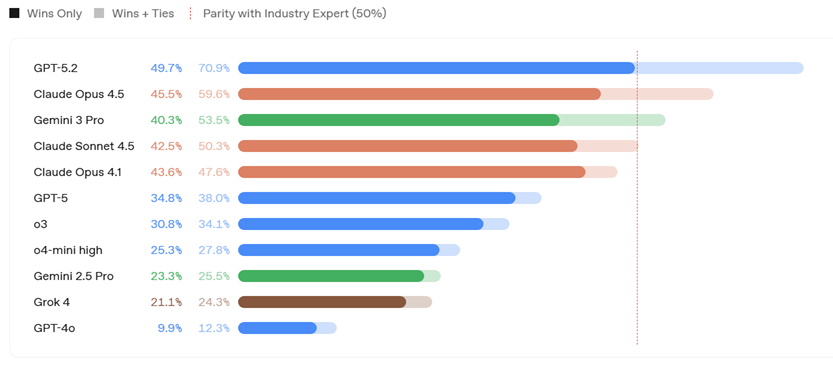
Source: OpenAI
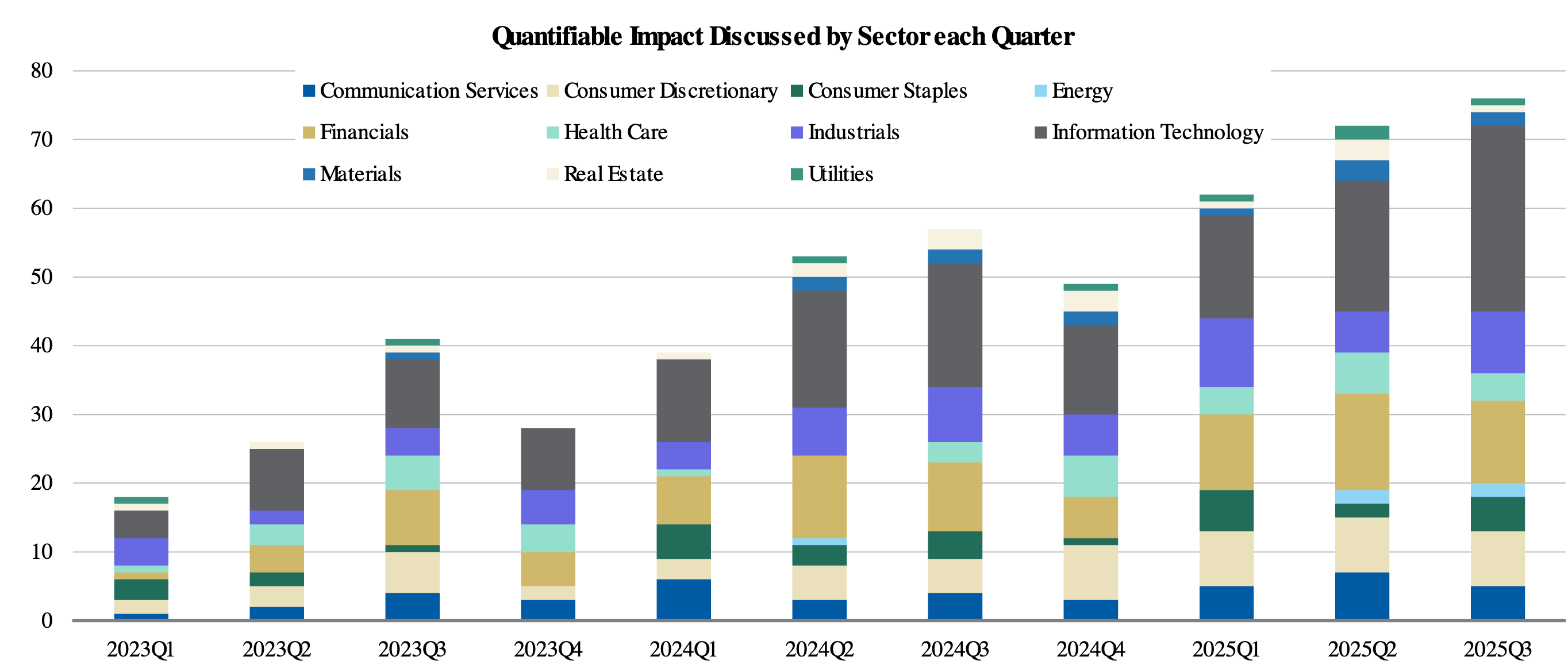
Market upside for AI Adopters remains under-appreciated despite a steady increase in the share of companies reporting quantifiable benefits. According to Morgan Stanley research, the percentage of identified “adopter” companies citing at least one quantitative impact reached 24% in 3Q25, up from 21% in 2Q25 and 15% in 3Q24. Within the broader S&P 500, mentions of measurable benefits rose to 15% in the third quarter of 2025, compared to 11% during the same period in 2024.
This trend is expected to persist as enterprise-wide AI tool deployment scales. These shifts hold critical implications for market leadership and margin expansion:
Market Leadership: AI enterprise adoption serves as a primary catalyst for a projected broadening in market leadership over the next 6–12 months, shifting beyond narrow tech concentrations in both price performance and earnings contributions.
Margin Expansion: Base-case projections suggest AI-driven efficiencies will contribute an incremental 40 bps in 2026 and 60 bps in 2027 to S&P 500 net margins.
Operating Leverage: These AI-enabled efficiencies are fundamental to the broader narrative of enhanced operating leverage across the index.
Discussions of Quantifiable Benefits from AI Are Rising

3. Low-cost AI solution providers attractive risk-reward, given the track record of success among these (primarily Chinese) companies in providing practical, low-cost business solutions that leverage AI technology.
As recently highlighted by MS China Internet and Telecoms analyst, Gary Yu:
“DeepSeek’s latest open-source LLMs, the DS V3.2 series, focus on efficiency, reasoning, and agentic capabilities. DS V3.2 ranks second only to Gemini 3.0 Pro in the coding benchmark and leads the world’s math benchmark. DS V3.2 also achieved a major technology breakthrough with DeepSeek Sparse Attention, reducing computing power use when processing long-text content.”
MS China Software analyst, Yang Liu, concluded:
“CIOs raised their 2025 IT budget growth forecast by 160bps sequentially to 7.4%, consistent with their initial readings for 2025 in 2H24 (7.2%). 48% of CIOs now expect upward revisions to their IT budgets in 2025, vs. 31% in 1H25, indicating strong momentum. CIOs project even stronger growth for 2026 at 12.6%, signaling a robust recovery and confidence in technology investment…. China IT outperformed NASDAQ significantly at the beginning of this year after the advent of DeepSeek, but this gradually faded amid robust AI infrastructure builds that drove growth in the US while China competitors remained relatively conservative. The MSCI China IT Industry index has underperformed the overall MSCI China index by 6ppts YTD, driven mainly by broader recovery in the China market...We have turned more positive on the China IT space amid early signs of optimism – valuations look reasonable and EPS has room to improve: From an earnings perspective, the MSCI China IT Industry has seen the most significant improvement in the hardware segment, supported by the NVIDIA supply chain in China, while semiconductors and software have had continued downward revisions. However, the CIO survey indicates potential upside to EPS growth moving into 2026.”
MS preferred plays on China AI-driven stocks are: Alibaba (BABA.N), Tencent (0700.HK), GDS (GDS.O), Xpeng (9868.HK), Xiaomi (1810.HK), PDD (PDD.O), and Foxconn Indl Internet (601138.SS).
Proprietary LLM developers, predominantly based in the United States, are projected to achieve attractive Return on Invested Capital despite the scale of required investment. While total capital expenditure for AI infrastructure—specifically data centers and power equipment—is forecast to exceed $3 trillion through 2028, this spend is countered by a projected $1.1 trillion revenue opportunity within the same timeframe. The investment thesis is further supported by a rapid expansion in profitability, with contribution margins expected to nearly double from 34% in 2025 to 66% by 2028. This trajectory suggests that the inherent scalability of proprietary models will drive significant operating leverage, effectively offsetting the substantial upfront infrastructure outlays.
MS projects >$1 trillion in AI revenue by 2028, with the majority driven by Consumer use cases:

Source: Company Data, Morgan Stanley Research.
LLM Capabilities to Enterprise Adoption in Action:
The majority of discussions of quantifiable benefits are tied to productivity gains (operational & process efficiency or overall performance improvement) or broad financial impacts (revenue growth/generation, cost savings, or investment & capital impacts). There are also a substantial number of mentions around sales, marketing & customer growth.
Category level mentions of AI Benefits:

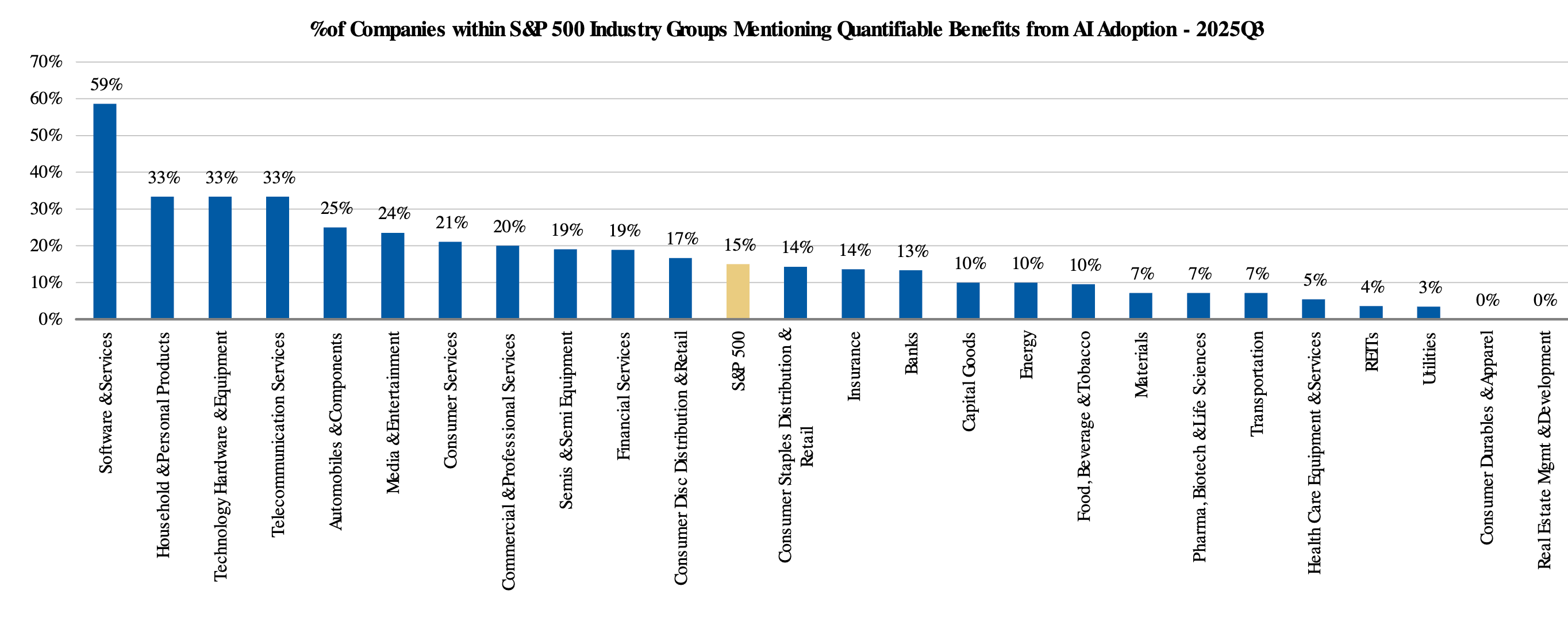
Tech companies are leading the way in discussing measurable impacts from AI, with frequent mentions of quantifiable benefits. Financials firms also show a notable number of mentions:
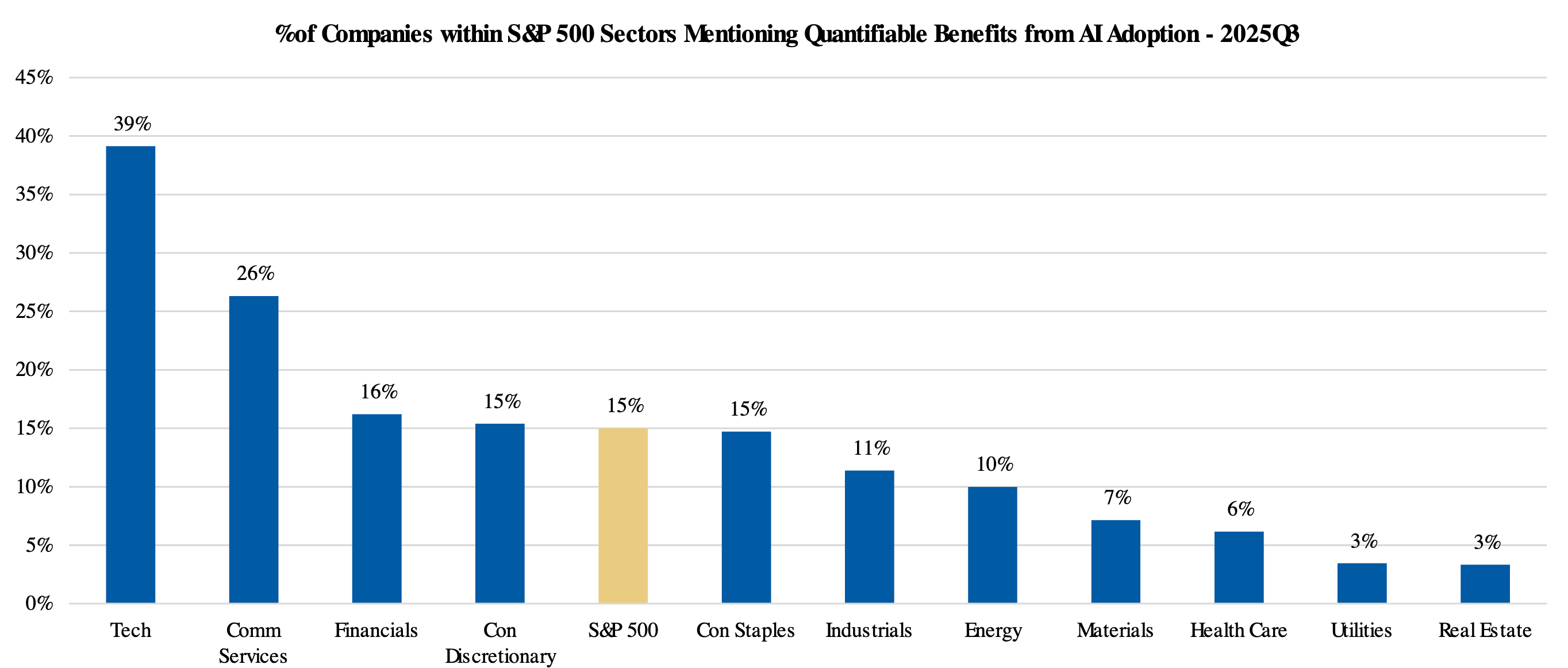
Percent of Companies within S&P 500 Industry Groups Mentioning Quantifiable AI-Related Impacts:
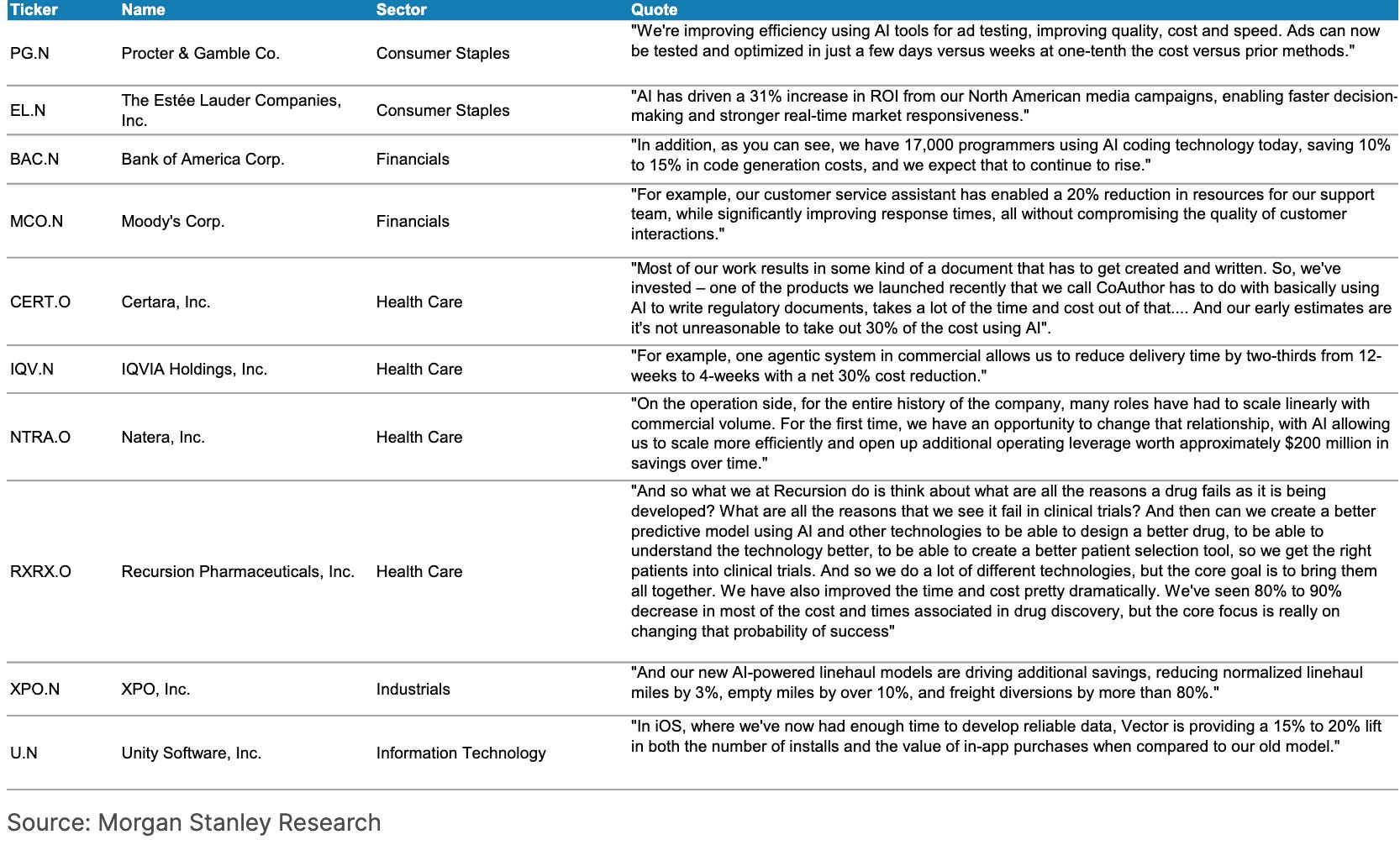
Financial Impact Examples:
Productivity Gains Examples:
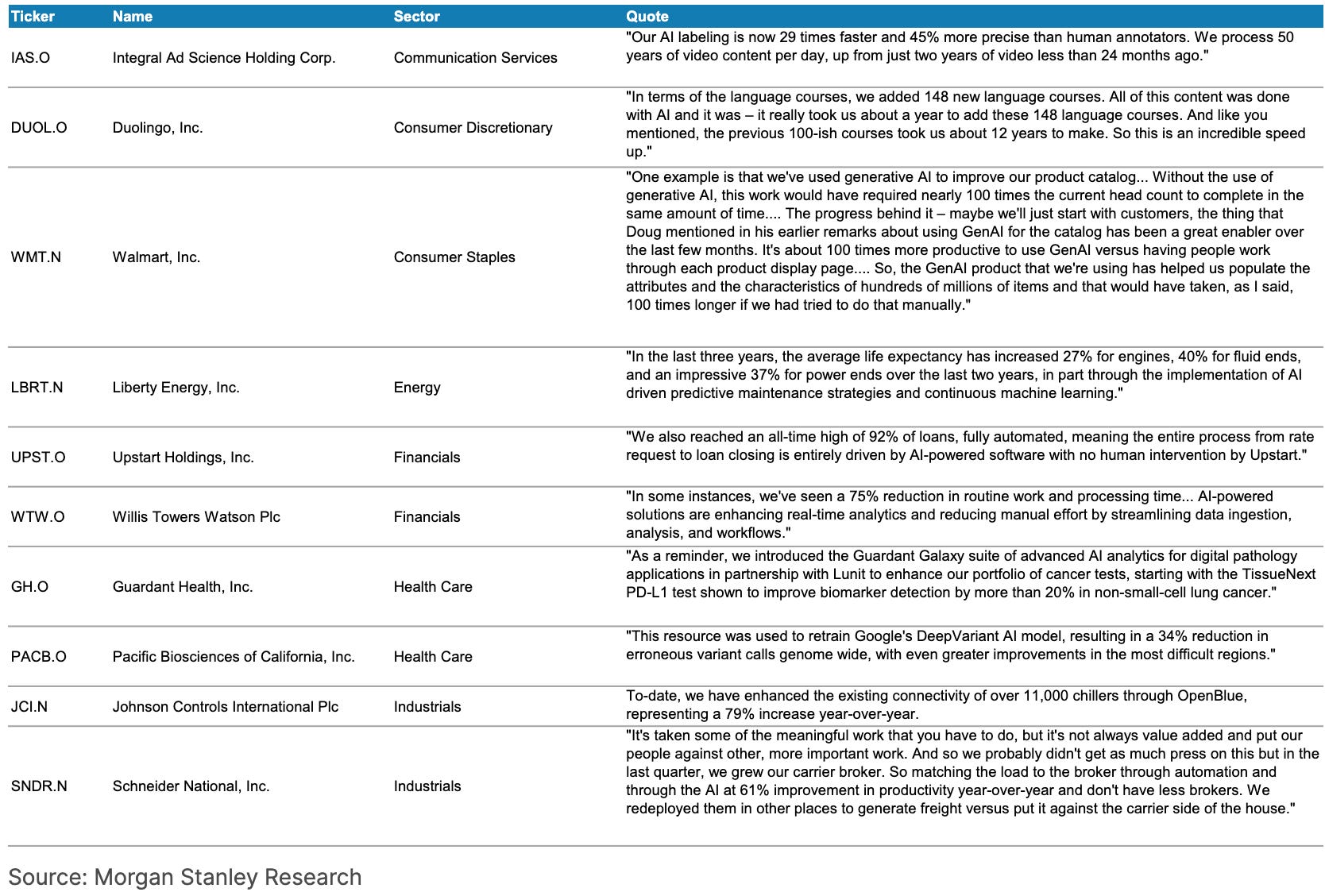
Sales, Marketing, & Customer Growth Examples: